
A team of students led by researchers in English and Computer Science will investigate a fundamental question about artificial intelligence: can machines be truly creative? Students will design experiments comparing human and AI storytelling, build datasets and computational tools to measure originality and surprise, and explore what current language models...

How do elites maintain power when the world around them is being radically transformed? Between the late sixteenth and early eighteenth centuries, England was reshaped by the explosive growth of global trade. Political and socio-economic elites had to adapt—or risk losing power. Who benefited from these changes, who lost out,...

A team of students will collaborate with a doctoral fellow in Computational Humanities and the Asian American Studies Librarian to develop a statistics-based Natural Language Processing toolkit to study the linguistic styles of Asian American short stories published between 1974 and 2024. This toolkit will support historians, literary scholars, and...
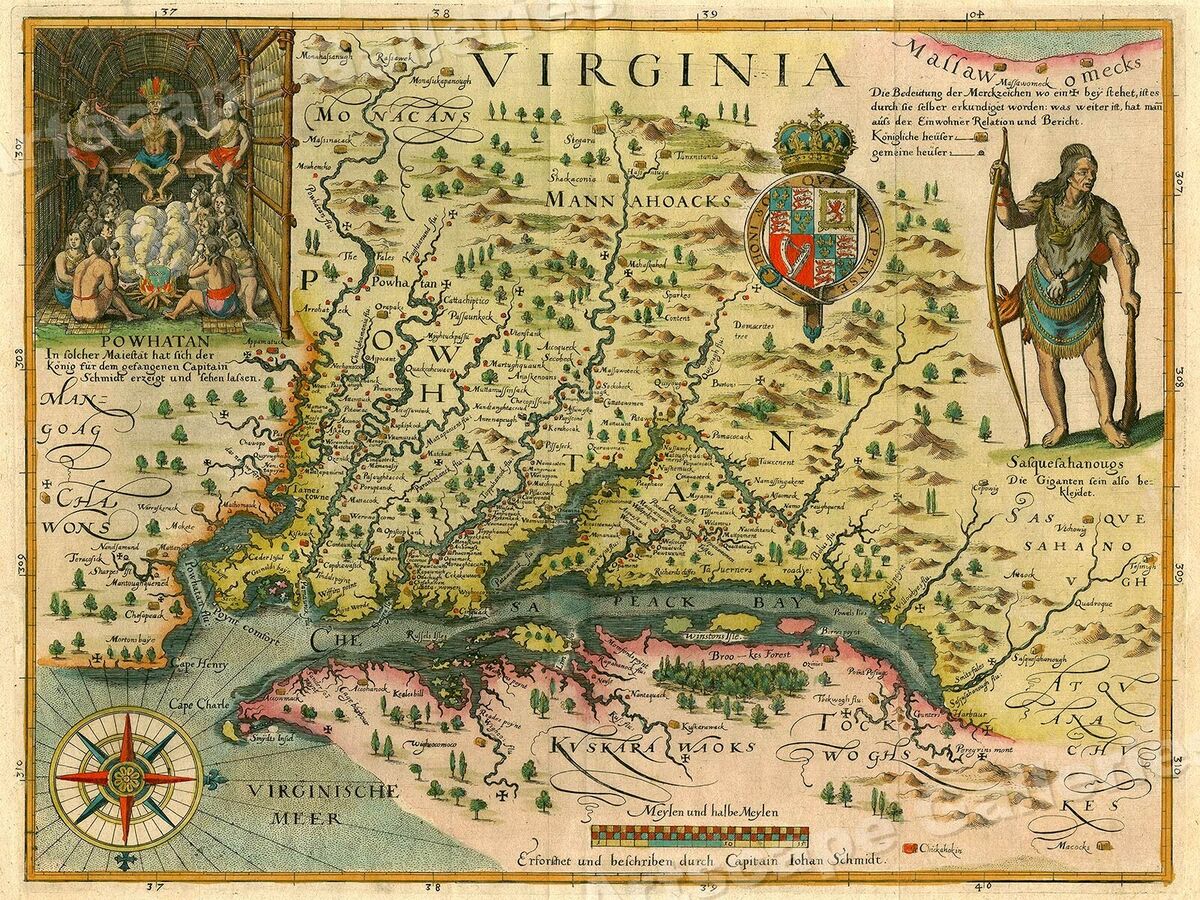
Is it ethically permissible to sell, buy, and use luxury goods? What labor practices do we tolerate to make these goods available? In the late Middle Ages and Renaissance, England was faced with an ever-growing supply of new and exciting goods, made possible by new trade routes to the New...
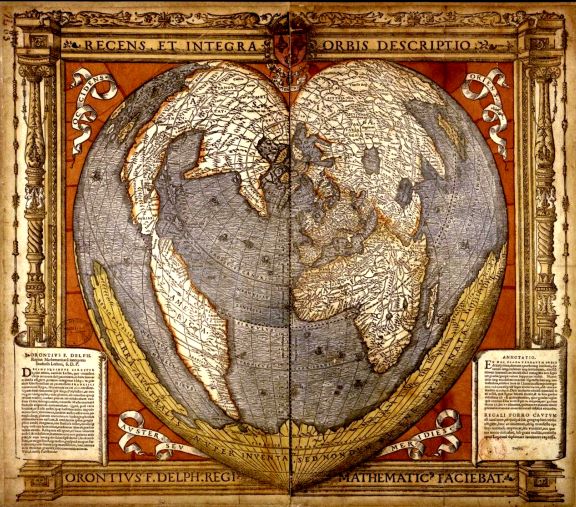
Is it ethically permissible to sell, buy, and use luxury goods? What labor practices do we tolerate to make these goods available? This project traces the early history of these questions as European powers started to exploit the natural resources and peoples of the New World. We want to trace...

A team of students led by professors Maurizio Forte, Classical Studies and AAHVS and Leonard White, Neurology, studied the embodied aesthetic experience engendered by real and virtual interactions with archeological ruins (“ruinscapes”) and virtual representations of places, spaces, and cultural artifacts associated with an ancient city. The focus will be...

A team of students led by an interdisciplinary group of faculty at the intersection of policy, economics, and computer science used statistical and machine learning methods to assess and map the discourse of speeches (1919-2022) by applied economists on food and agricultural policy. Understanding the historical underpinnings of these policies...

Is it ethically permissible to sell, buy, and use luxury goods? What labor practices do we tolerate to make these goods available? In the late Middle Ages and Renaissance, England was faced with an ever-growing supply of new and exciting goods, made possible by new trade routes to the New...

A team of students led by a data scientist at NetApp developed the means to evaluate technical documentation through machine learning techniques. Students identified features of language and documents that can be used to demonstrate how effective that documentation is at communicating technical specifications. Additionally, students applied machine learning methods...

Using digitized card catalogs from the David M. Rubenstein Rare Book and Manuscript Library, a team of students explored extracting structured data from over 115,000 subject cards to develop searchable and sortable descriptions of manuscript and archival collections. They prepared the digitized subject cards for online access in the Internet...

A team of students led by Co-Principal Investigators Dr Jenny Immich and Dr Vicky McAlister will develop a geospatial methodology to automate data analysis originating from small unmanned aerial vehicles (SUAV) that seeks to identify the homes of ordinary medieval people within the modern Irish landscape. Known as aerial archeology,...

This project transforms an inaccessible audio archive of historic North Carolina folk music colllected by Frank Clyde Brown in the 1920s-40s into a vital, publicly accessible digital archive and museum exhibition. Project Team Trudi Abel & Victoria Szabo Louise Mentjes, Laura Williams, Winston Atkins, Craig Breaden Meghan O’Neill & Philip MacDonald Peter Ciporin, Ruochen Hao, Laura...

This is an overview of intellectual and technical adventures rooted in the project of organizing an exhibition at the North Carolina Museum of Art (NCMA) that reunites, for the first time in more than 100 years, the panels of the 14th-century Italian St. John altarpiece by Francescuccio Ghissi. A more...

Platypus is a software solution that comes both as a standalone application and a Photoshop plugin. It is specifically designed to digitally remove cradling artifacts in X-ray images of paintings on panel. This project was made possible thanks to the financial support of the Kress foundation. Read more and download...

Anna Yanchenko and Sayan Mukherjee Algorithmic composition of music has a long history and with the development of powerful deep learning methods, there has recently been increased interest in exploring algorithms and models to create art. We explore the utility of Hidden Markov Models in composing classical piano pieces from...

This project is a collaboration of researchers from the Rhodes Information Initiative and a team located at Tel-Aviv University. The team tackles various questions regarding literacy in the ancient kingdoms of Judah and Israel of the First Temple period (Iron Age) through a computational analysis of handwritten documents. We have...

Is there a right type and amount of consumption? The idea of ethical consumption has gained prominence in recent discourse, both in terms of what we purchase (from fair trade coffee to carbon off-sets) and how much we consume (from rechargeable batteries to energy efficient homes). These modes of ethical consumerism assume...

Annie Xu (Rice, CEE), Liuren Yin (ECE), and Zoe Zhu (Data Science) spent ten weeks analysing usage data for MorphoSource, a publicly available 3D data repository maintained by Duke University. Working with Python and Tableau, the team developed an interactive dashboard that allows MorphoSource staff to explore usage patterns for...

After London was destroyed during the Great Fire of 1666, it was reconstructed into the “emerald gem of Europe,” a utopian epicenter focused on England’s political and economic interests. For whom was the utopia constructed? Who determined its architectural choices? And what did such a utopia look like in seventeenth-century...

Is there a right type and amount of consumption? The idea of ethical consumption has gained prominence in recent discourse, both in terms of what we purchase (from fair trade coffee to carbon off-sets) and how much we consume (from rechargeable batteries to energy efficient homes). Concern with the morality...
Showing 1-20 of 42 results