A new model is developed for joint analysis of ordered, categorical, real and count data. In the motivating application, the ordered and categorical data are answers to questionnaires, the (word) count data correspond to the text questions from the questionnaires, and the real data correspond to fMRI responses for each...

Paclitaxel (Taxol) is a small molecule drug belonging to the taxane family. It is one of the most commonly used chemotherapeutics, used for treatment of many cancers, as a monotherapy or in combination with other drugs to treat breast, lung and ovarian cancer as well as Kaposi’s sarcoma. Taxol is on the World Health Organization’s (WHO) List...

A team of students led by researchers in the Duke River Center will develop a publicly available and accessible website to serve as a portal to explore diverse and extensive datasets detailing the quality of waterways and the effectiveness of management efforts to reduce risks associated with chemical contaminants, stormwater...

Fluid mechanics is the study of how fluids (e.g., air, water) move and the forces on them. Scientists and engineers have developed mathematical equations to model the motions of fluid and inertial particles. However, these equations are often computationally expensive, meaning they take a long time for the computer to...

Large publicly available environmental databases are a tremendous resource for both scientists and the general public interested in climate trends and properties. However, without the programming skills to parse and interpret these massive datasets, significant trends may remain hidden from both scientists and the public. In this data exploration, students,...

Most phenomena that data scientists seek to analyze are either spatially or temporally correlated. Examples of spatial and temporal correlation include political elections, contaminant transfer, disease spread, housing market, and the weather. A question of interest is how to incorporate the spatial correlation information into modeling such phenomena. In this...
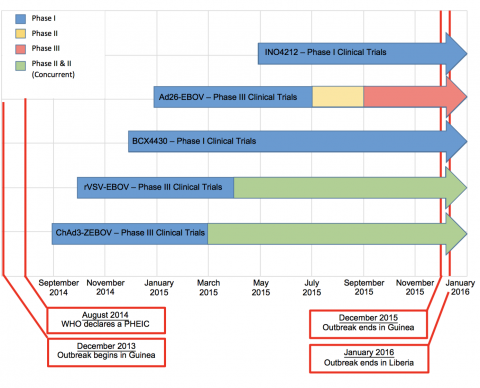
With the significant international consequences of recent outbreaks, the ITP Lab conducted extensive stakeholder interviews and macro-level health policy analysis to expose gaps in pandemic preparedness and develop legal frameworks for future threats. Project Team Kushal Kadakia, Public Policy & Global Health Nora Ghanem, Public Policy & Global Health Niveen Hennein, Public Policy...

A team of students led by the Duke World Food Policy Center’s Ag economist Norbert Wilson and electrical and computer engineering professor Leslie Collins and research professor Boyla Mainsah will analyze agricultural research funding to understand whether USDA’s National Institute of Food and Agriculture (NIFA) has prioritized Ag production and...

A multidisciplinary team of students will work at the intersection of data science, policy, and food systems to analyze critical agricultural research shaping the science of food, agriculture, and the environment in the United States. Using natural language processing and machine learning, the team will explore federal grant records to...

A team of students led by an interdisciplinary group of faculty at the intersection of policy, economics, and computer science used statistical and machine learning methods to assess and map the discourse of speeches (1919-2022) by applied economists on food and agricultural policy. Understanding the historical underpinnings of these policies...

Varun Nair (Economics, Physics), Paul Rhee (Computer Science), Jichen Yang (Computer Science, ECE), and Fanjie Kong (Computer Vision) spent ten weeks helping to adapt deep learning techniques to inform energy access decisions. Click here to read the Executive Summary Faculty Lead: Kyle Bradbury Project Manager: Fanjie Kong
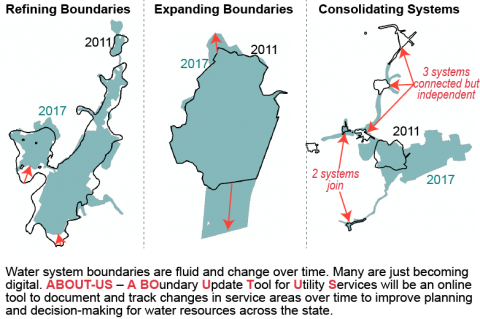
We all need water to survive but how many of us really know where our water comes from? Team 3 has created a functioning website from scratch to give consumers more easily accessible information about who provides their water and how supply looks in relation to the past 30 years....

In this two-day, virtual data expedition project, students were introduced to the APIM in the context of stress proliferation, linked lives, the spousal relationship, and mental and physical health outcomes. Stress proliferation is a concept within the stress process paradigm that explains how one person’s stressors can influence others (Thoits...

A team of students, collaborating with Professors Mike Bergin, David Carlson, and PhD Candidate Zach Calhoun developed a modeling approach to estimate heat stress in urban areas. Students will further develop a dataset consisting of high-resolution temperature and relative humidity observations in over 60 cities (https://www.heat.gov/pages/mapping-campaigns), satellite imagery and meteorological...

A team of students led by Dr. Liz DeMattia (Duke University Marine Lab) and Dr. Rachel Noble (UNC-IMS) will explore the Community Science Initiative’s AdoptADrain citizen science data collected during the 2021/2022 academic year (the first year of the program). Potential data analyses will include: collating, organizing, comparing and contrasting,...
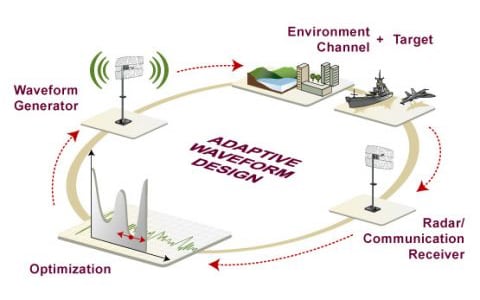
Pryia Juarez (BME/ECE), Jonathan Pilland (ECE/BME), and Matthew Traum (CS/Econ) spent teen weeks analyzing sensor data synthesized by an agile waveform generator. The team used deep reinforcement learning techniques to understand the performance of different synthetic agents representing potential attackers to the sensor system.

Our team used artificial intelligence to help Duke University Management Company (DUMAC) operate more efficiently by building a cost optimization tool and analyzing and visualizing venture capital data. In our first project centered around cost optimization, we designed a Python script that suggests optimal cash transfers between prime brokers. In...

A team of students led by Ph.D. student Yu Wei and assistant professor Tong Qiu from the Spatial Ecology and Environmental Data Sciences (SEEDS) lab will utilize cutting-edge remote sensing technologies—including hyperspectral imagery and airborne Light Detection and Ranging (LiDAR)—combined with an advanced deep learning framework to enhance forest biodiversity...
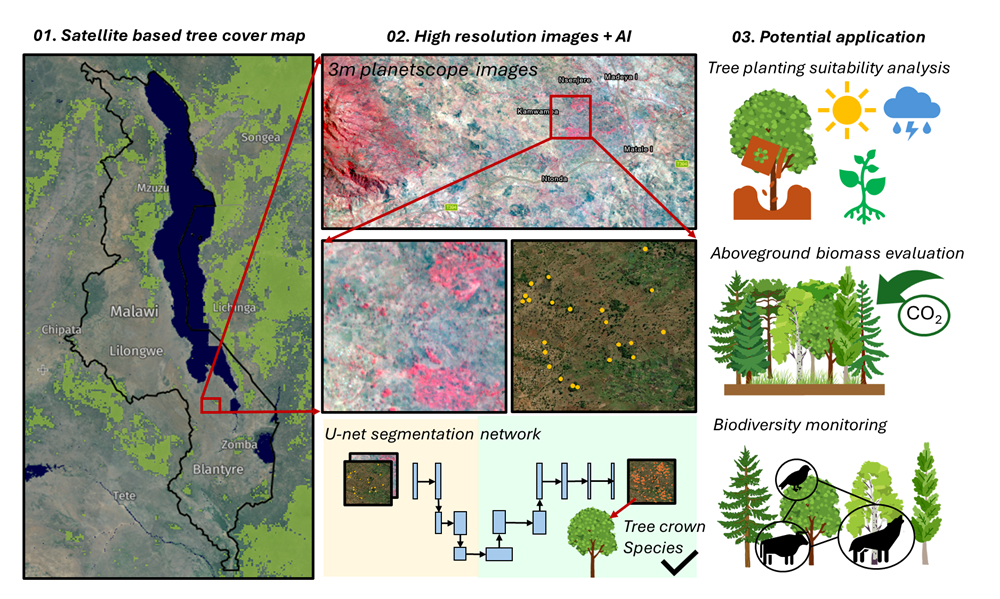
A team of students will combine cutting-edge, high-resolution satellite imagery with a state-of-the-art AI and pattern-recognition framework to improve restoration outcomes across sub-Saharan Africa. Students will map trees both inside forests and across farms and villages using a deep learning model, then link those maps to socioeconomic factors and biophysical...
This is an innovative project that explores the intersection of artificial intelligence and mathematics. This initiative aims to leverage AI’s capabilities in pattern recognition and exhaustive search to tackle complex problems in discrete mathematics, such as finding counterexamples to open conjectures. By framing these mathematical challenges as computational problems, students...
Showing 1-20 of 388 results