
Our aim was to introduce students to the wealth of possibilities that human genotyping and sequencing hold by illustrating firsthand the power of these datasets to identify genetic relatives, using the story of the Golden State Killer’s capture with public genetic databases.
Graduate Students: Ryan Campbell and Jenn Coughlan, Duke Biology
Course: BIO190S, Genetics and Evolution in Humans
Building on recent coursework discussing genetic differences between human populations we discussed the underlying math used to describe these differences. We also covered the technologies that allows us to quickly and affordably measure genetic differences, the same ones that make consumer products such as 23&Me possible. After the introductory lecture students split into groups to discuss articles related to the case, which gave them an opportunity to ask questions in an informal setting and learn from each other.
After the introduction and group work we introduced the students to R and R markdown files, which allow the user to combine typed notes and other organizational tips with code to be executed. The students were provided with a default R markdown file (.Rmd) which they ran in R while making small changes. The file also contained their homework assignment, consisting of questions to be answered, and they completed this assignment directly in the R markdown file.
In running this R markdown file the students downloaded a database with multiple individuals genetic information (HapMap). This information was stored as genotypes at a large number of Single Nucleotide Polymorphisms (SNPs), repeated over several hundred individuals. The students were asked to summarize the dataset and investigate to determine how many human populations it consisted of (Fig 1).
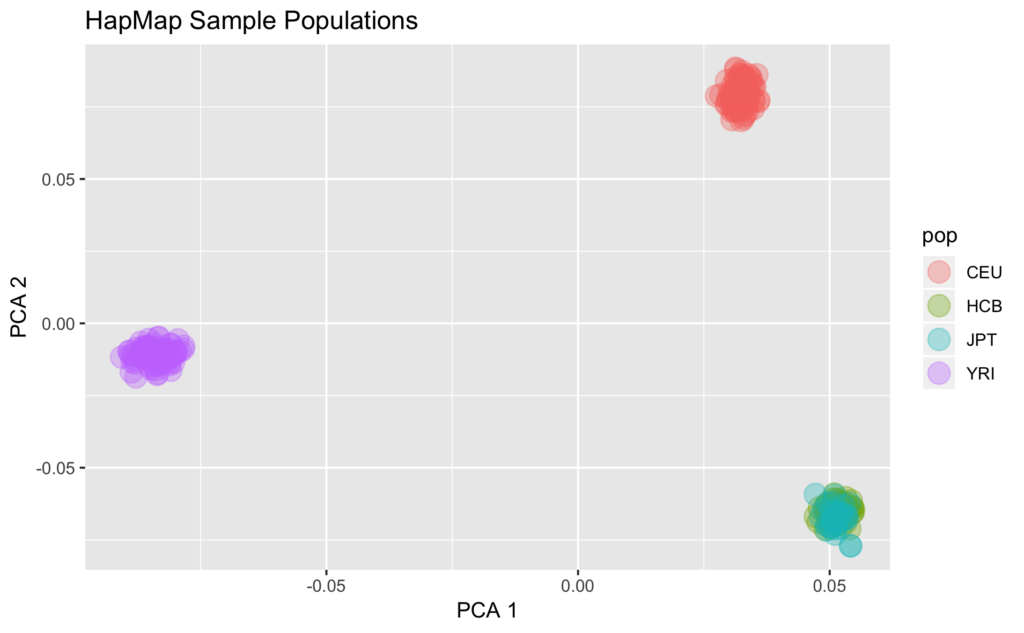
Once students have been acclimated to the R environment, the dataset, and the markdown file they drew a random population to simulate the membership in common consumer genetic databases such as GEDMatch, which are largely Northern European. In pairs they picked a random “criminal.” One partner has code to pick a Northern European criminal while the other partner has code to pick an individual not of Northern European ancestry. They then query the database for the level of genetic similarity (kinship) with their focal criminal, and have to find samples that would help them conduct their criminal investigation. They are looking for an individual with high kinship to the criminal as that would be a close family relative and could identify them.
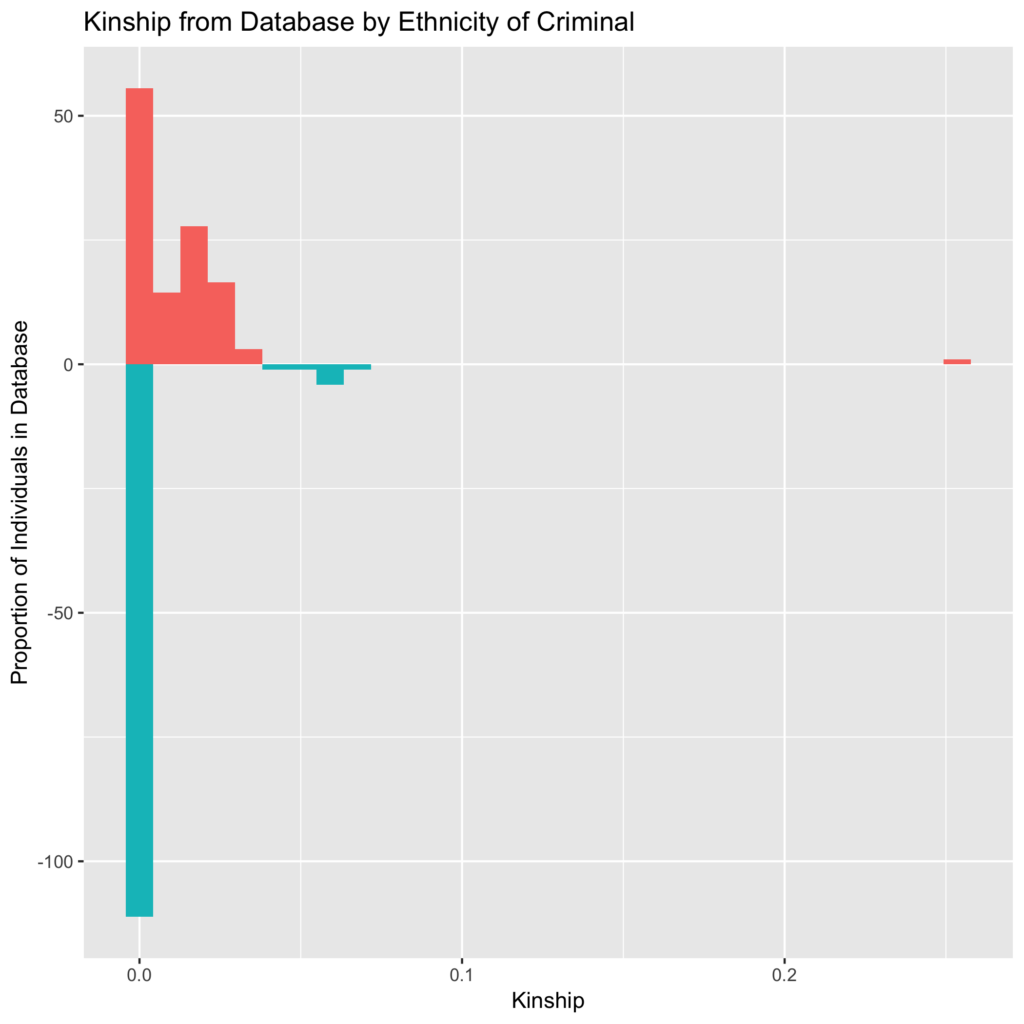
Finally the students are asked to assess the differences between the outcomes of each partner, summarized in Figure 2. Because the database has far more Northern European samples, the partner given a criminal of this ancestry (red in the figure) will have found a much closer relative than the criminal of a different ancestry (blue in the figure).
Regardless of what the future holds for these students, they will almost assuredly be impacted by the sequencing and genotyping of human genomic data. Whether directly interacting with this type of data through careers as research scientists and medical doctors or indirectly learning of the implications of their genetic code through the health of themselves or family members, the impending genomic revolution in medicine will impact nearly everyone. We hope that through this module we have familiarized students with the nature of genetic data that is presently available as well as the usefulness and power of data analysis.
Sources: Graham Coop blog post – gcbias.org Atlantic Golden State Killer GEDmatch site – GEDmatch Cryptic Distant Relatives Are Common in Both Isolated and Cosmopolitan Genetic Samples Consumer DNA Testing
Course Files

