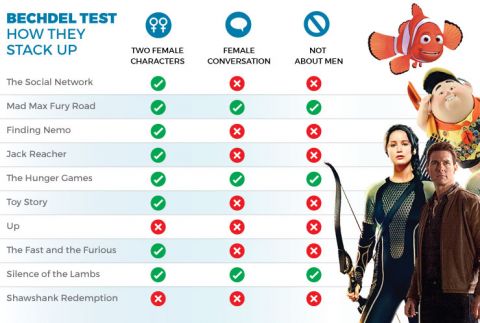
Selen Berkman (ECE, CompSci), Sammy Garland (Math), and Aaron VanSteinberg (CompSci, English) spent ten weeks undertaking a data-driven analysis of the representation of women in film and in the film industry, with special attention to a metric called the Bechdel Test. They worked with data from a number of sources, including fivethirtyeight.com and the-numbers.com.
Project Results: The team showed that movies which pass the Bechdel test, which requires that a movie have at least two female named characters who talk to each other about something other than a man, have a statistically significant higher return on investment when compared to films that do not.
They also demonstrated a clear positive relationship between the number of women working on the production of a film and the percentage of female dialogue. Finally, the team expanded the binary Bechdel test into a continuous score called the Bechdel score, and they demonstrated a clear positive correlation between this score and the percentage of overall film dialogue spoken by female characters.
Click here for the Executive Summary
Faculty Lead & Project Manager: Stefan Waldschmidt
Room 351: Sharing Project Space and Coding
“I gained valuable program management experience. Given that after the program was over I got hired as a consultant manager at CollegeVine, I’d say it paid off.” — Stefan Waldschmidt, Faculty Lead, Project Manager and PhD Candidate, English at Duke University






