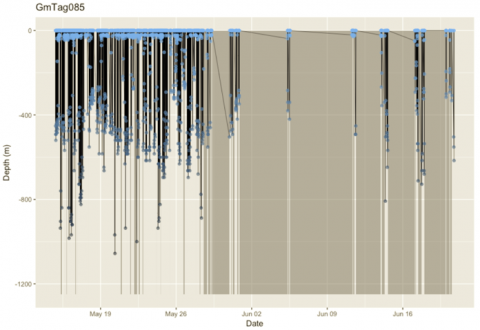
Introduce NBA and MLB datasets to undergraduates to help them gain expertise in exploratory data analysis, data visualization, statistical inference, and predictive modeling.
Graduate students: Joe Futoma and Ken McAlinn, PhD students, Statistical Science
Faculty instructor: Mine Cetinkaya-Rundel
Course: STA 112 (Data Science)
Applications:
- Assessing home field advantage
- Determining long term trends
- Predicting game outcomes