We led a 75-minute class session for the Marine Mammals course at the Duke University Marine Lab that introduced students to strengths and challenges of using aerial imagery to survey wildlife populations, and the growing use of machine learning to address these “big data” tasks.
Graduate students: Gregory Larsen and Patrick Gray, Marine Science & Conservation
Faculty collaborator: Andrew Read
Course: “Marine Mammal Conservation” (BIOLOGY 376A)
Overview
In the first half of the class period we gave a presentation introducing the basic principles of aerial wildlife surveillance, unoccupied aircraft systems (drones) for research, big data challenges in wildlife monitoring, the basic principles of machine learning and deep learning, different types and applications of deep learning, and the growing use of deep learning in the field of ecology. At the end of our lecture we revisited a research example from the lecture, and we spent the second half of the class guiding the class through the process of accessing and exploring the data from that example, annotating those data as training data for a convolutional neural network, and then proceeding step-by-step through code to set up and train a convolutional neural network using those data. Before class we provided a reading assignment of two articles providing background for the topic of our data expedition, and after class we gave an assignment on evaluating the efficacy of the technique and critically considering its applications in the field.
Expedition Learning Goals
- Understand with the roles of aerial imagery and wildlife surveillance in conservation.
- Become familiar with the basic components and capabilities of drone systems.
- Understand the principles, families and applications of machine learning and deep learning.
- Recognize opportunities and challenges of deep learning with big data in the field of ecology.
- Create training data for a supervised classification algorithm.
- Set-up, train, and execute a convolutional neural network on ecological imagery data.
- Become familiar with remote sensing imagery, the Jupyter Notebook environment, and the elements of a supervised machine learning algorithm.
Introduction
Aerial surveys are a mainstay of wildlife conservation, having numerous advantages over on-the-ground survey techniques. And, with the advent of unoccupied aircraft systems (UASs), aerial mapping and surveillance is a growing component of the field of environmental remote sensing. UAS technologies are increasingly able to provide vast coverage of study regions in high resolutions with ever decreasing costs, and enormous amounts of data are being collected whose analysis is often limited by the bottleneck of human image processing. This bottleneck is not specific to the field of wildlife conservation, however, and computer scientists are now applying machine learning techniques to automate the process of semantic image analysis.
In the field of marine mammal research and management, aerial surveys are often used to survey populations of seals and sea lions when they come on land to breed and molt. Aerial photographic surveys can capture hundreds or thousands of animals at a time over vast habitats of coastal terrain; but it can be a time-consuming and error-prone task for human analysts to identify, locate and count all of these animals among the imagery. Such tasks fall under the subfield of ‘image classification’ in machine learning, where deep learning algorithms are increasingly proficient at extracting image features to identify objects of interest. Convolutional neural networks (CNNs) are one class of deep learning algorithms that are able to efficiently process example images (or ‘training data’) to establish a set of rules for accurate image classification. In this data expedition, we used a dataset of aerial imagery from a survey of gray seals (Halichoerus grypus) in Nova Scotia to create training data for a CNN, and then executed steps of python script to train that CNN using our data. We then examined example results from this process to evaluate the accuracy of our trained algorithm overall, considering the specific cases in which failure or ‘class confusion’ appear to occur.
Before-Class Readings
We assigned this case-study article to introduce students to the specific type of data with which they will be working in our data expedition. This paper describes the methods and scientific context of aerial wildlife surveys with seal species, showcasing and comparing a variety of aerial imaging techniques in the context of gray seal research and management. We intend that this background will prime students for the data that they encounter during our exercise and underscore the potential contribution of deep learning to research with marine mammals.
We assigned this broad review article to introduce students to the opportunities and increasing applications of computer vision in the field of ecology. This paper situates our data expedition among a diversity of applications with different species, different wildlife imaging data, and different research questions. We intend for this context to help our students to consider new and diverse applications of deep learning in the fields of ecology and conservation beyond the specific application featured in our exercise.
The Data
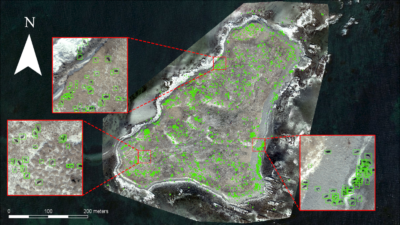
Our data expedition uses a photomosaic of Hay Island, Nova Scotia, collected in February 2015 during the gray seal breeding season. The photos are visible light imagery collected at 3 cm ground sampling distance (GSD), so each pixel represents 3 cm² of ground. The images were collected using a Sensefly eBee fixed-wing unoccupied aircraft vehicle flown with eMotion mission planning software, and were stitched into an orthomosaic product using Pix4D software.
Photomosaic of Hay Island, Nova Scotia, featuring a breeding colony of gray seals

These data were prepared for the data expedition by (1) splitting the mosaic into tiles that can be loaded into a CNN training algorithm, and (2) annotating each tile to mark seal locations to be used as training data for the CNN.
The Code
The hands-on component of this data expedition uses a Jupyter Notebook document that guides students through the process of loading annotated imagery into a CNN for training. The code is written in python and executes in a Google Co.lab browser-based virtual machine. It loads a RetinaNet CNN model, trains the model, and then executes the trained model on the entire dataset of imagery.
The code is annotated and presented in a stepwise fashion such that users who are not familiar with python can still understand conceptually what is occurring as they execute each step sequentially; and users who are familiar with python can access the code in full to understand and, if desired, customize or replicate precisely what is occurring at each step of the process.
We have hosted an output product, prepared beforehand using this code, on ArcGIS online for the students to explore as a visualization of the CNN’s results.
Image classification results of our CNN (green rectangles) trained to locate gray seals and applied to the photomosaic of Hay Island, Nova Scotia
After-Class Exercise
After the class period we assigned a short two-part exercise to wrap up some key takeaways from our data expedition.
The first part is an exercise on evaluating CNN outputs. In text we introduce students to the standard metrics and equations for “precision,” “recall,” and the “F1 score” that combines the two. Using a subset of data from our in-class exercise, we ask students to calculate these metrics, focusing on the simple math involved, and how these metrics reflect different types of failure in our CNN output.
The second part prompts students to consider opportunities where machine learning can contribute to research in the field of the course (here, marine mammals). We invite students to explore the literature and find a research paper that studies marine mammals, to consider the data involved in that research, the potential benefits and drawbacks of applying machine learning to that research, and what type of machine learning would be most appropriate for this study. We hope that this exercise encourages students to consider new applications of machine learning beyond the scope of our exercise and potentially more aligned with their interests.