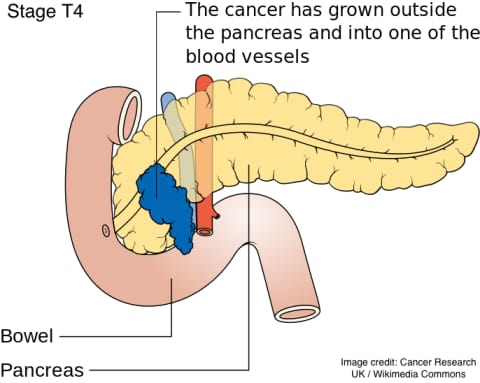
Furthering the work of a 2016 Data+ team in predictive modeling of pancreatic cancer from electronic medical record (EMR) data, students Siwei Zhang (Masters Biostatistics) and Jake Ukleja (Computer Science) spent ten weeks building a model to predict pancreatic cancer from Electronic Medical Records (EMR) data. They worked with nine years worth of EMR data, including ICD9 diagnostic codes, that contained records from over 200,000 patients.
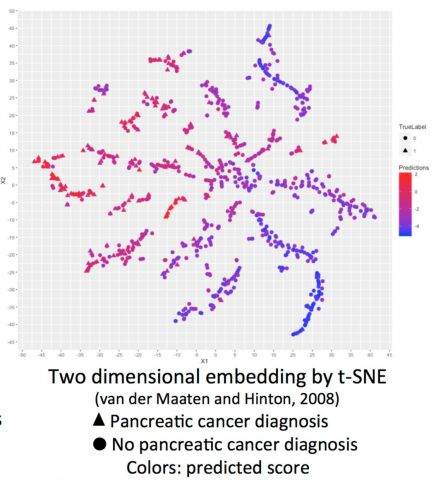
Project Results: The team began with exploratory data analysis that illustrated median times of appearance and frequency of specific ICD9 codes, with an eye toward understanding the relation between these statistics and pancreatic cancer diagnosis. They then trained a topic model which predicted past pancreatic cancer diagnosis with high accuracy (93 percent AUC) from ICD9 codes. Finally, they used the topic model outcomes to identify a pool of high-risk patients for potential future study.
Click here for the Executive Summary
Project Leads:
Joseph Lucas, PhD
Project Manager: Tyler Massaro