In this work, we turn musical audio time series data into shapes for various tasks in music matching and musical structure understanding.
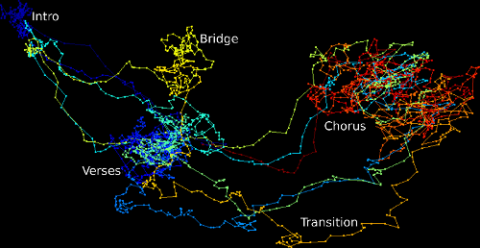
In particular, we use sliding window representations of chunks of audio to create high dimensional time-ordered point clouds, and we extract information by analyzing the geometry of these clouds. We have shown, for example, that sequences of these shapes can be used to identify two different versions of the same song, or “cover songs.” We have also shown that both local and global musical properties can be expressed in geometric language. For instance, hip hop is very “wiggly” while classical music is very “smooth.” Choruses and verses tend to live in distinct clusters connected by paths, and “bridges,” or detours to a different musical idea, show up as large loops.
Contact
Electrical and Computer Engineering
chris.tralie@gmail.com