![]() Data+ (and Climate+, which is under the Data+ umbrella) are research experiences that welcomes undergraduate and masters students interested in exploring new data-driven approaches to interdisciplinary challenges. It is suitable for students from all class years and from all majors. Students join small project teams (at most 3 undergrads and 1 master’s student per team), working alongside other teams in a communal environment. They learn how to marshal, analyze, and visualize data, while gaining broad exposure to the modern world of data science.
Data+ (and Climate+, which is under the Data+ umbrella) are research experiences that welcomes undergraduate and masters students interested in exploring new data-driven approaches to interdisciplinary challenges. It is suitable for students from all class years and from all majors. Students join small project teams (at most 3 undergrads and 1 master’s student per team), working alongside other teams in a communal environment. They learn how to marshal, analyze, and visualize data, while gaining broad exposure to the modern world of data science.
The projects come from an extremely diverse set of subject areas. It is our hope that students will be able to both work deeply into their specific project and get a very broad picture of most of the skills needed for modern data science.
Participants will receive a $5,000 stipend, out of which they must arrange their own housing and travel. Funding and infrastructure support are provided by a wide range of departments, schools, and initiatives from across Duke University, as well as by outside industry and community partners.
Data+ has returned to 100% in-person participation. Participants may not accept employment or take classes during the program; this requirement is strictly enforced and non-negotiable.
Due to the nature of the data involved in some of the projects, human subjects research training will be required of all participants and will be provided after admission to the program. With each project, we have attempted to list potential majors and/or interests that might be most interested in the project, but these should not be seen as requirements in any way! Quantitative STEM majors like mathematics, computer science, statistics, and electrical engineering are relevant to all.
Expectations
Participants are expected to participate full-time in person with their teams and may not accept employment or take classes for the duration of the program. If a student cannot be present for the entirety of the program, they must provide advance notice to program administrators in writing. Excessive absence may impact a student’s stipend.
Program Details
Data+ provides participants with a non-compensatory award. On campus students receive $1,000.00 in addition to the housing and a meal plan; off campus students receive $5,000.
To receive your first award payment on time, visit DukeHub and set up direct deposit before May 1. Payments are generally made at the end of each month of the program (May, June, and July).
2026 program dates are May 18-July 24th.
Parking
If you have a valid parking permit for the current academic year, it is valid until mid-August. Beginning in early May, you can purchase 1-day, 7-day, and 30-day permits valid at 300 Swift Ave., Blue Zone, and East surface lots from Parking and Transportation. Buses and vans will also run. For questions, contact tranpark@duke.edu.
For International Students
Complete all Foreign National/Visa forms emailed to you ASAP to ensure timely payment. We are not responsible for late payments due to late submissions.
Without a SSN/ITIN, students cannot claim tax treaties, even if their country of origin has an agreement with the US (this means your stipend payment will have steep taxes applied). Students also cannot claim the treaty retroactively when they receive their ITIN, so please be sure to get this paperwork going and provide your ITIN as soon as possible!
Although these students may still receive their first payment, Corporate Payroll reserves the right to withhold their second payment until they receive an ITIN.
When the student receives their ITIN, they will still need to provide it to Corporate Payroll, even if they have received both payments.
*Some international students will have taxes taken from their stipend if their country does not have a tax treaty with the US. Please consult with corporate payroll about stipend taxes for international students.*
DKU students:
May participate, but there are additional considerations:
The Duke Office of DKU Relations must agree to sponsor the student specifically for the +Programs. Please reach out to dkurelations@duke.edu to confirm sponsorship eligibility before accepting your offer.
If a DKU student does not have an ITIN or a SSN, they must be physically present in the US in order to apply for one. This can potentially cause delays in payment.
If you do not have a U.S. Taxpayer ID in the form of a Social Security Number (SSN) or Individual Taxpayer Identification Number (ITIN), take your Data+ offer email to Duke Visa Services (no appointment necessary) to request one. It can take 10 weeks to receive an ITIN. If Duke does not have your ITIN, your award payment may be delayed.
Checks and US tax forms cannot be mailed outside of the US. If you need your Duke mailbox to remain open during the summer, contact dukepostoffice@duke.edu.
Get Involved
Project Managers
Learn how to become a Data+ project manager.
Partners
Industry partners are essential to Data+. Learn how to become a partner.
Contact Us
Email Greg Herschlag with your questions or thoughts about the Data+ program.
News
Linden James Showcases Summer Research at National Math Meeting
Congratulations to Linden James for a successful presentation at the Joint Mathematics Meetings in Washington, D.C.! Linden and their Data+ teammates were invited to showcase their summer research during a competitive poster session earlier this month. Linden has shared a summary of the event and the professional milestones reached during the trip.
Check out the the full report (PDF) to read more.
Donate to Data+

From Our Data+ Students






Alumni Videos
Hear from alumni on their experiences in the Data+ program, from what they learned to where they are now.

Data+ by the Numbers
weeks during the summer
undergraduates per team
grad student mentors per team
projects sharing ideas and code
Data+ Projects




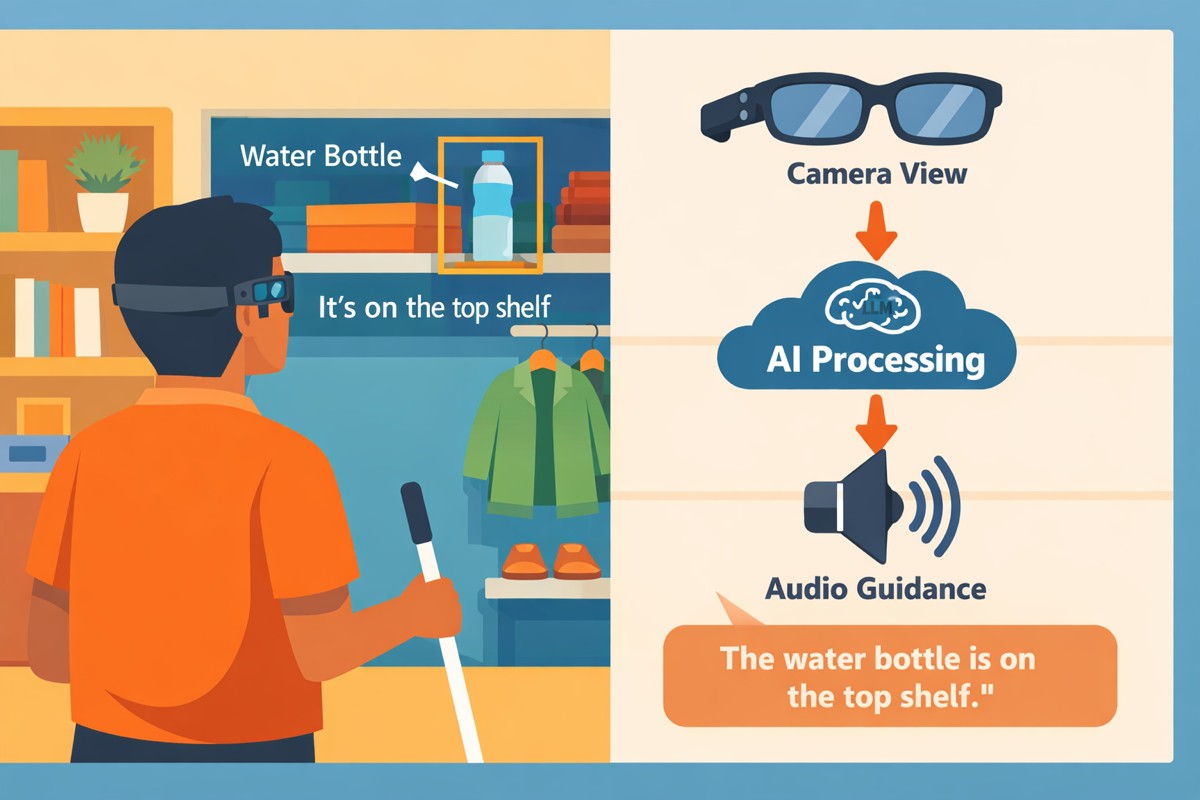





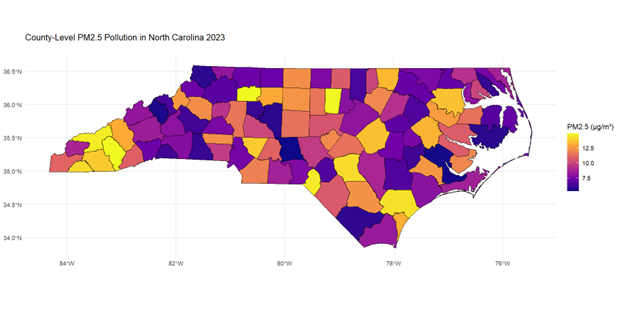
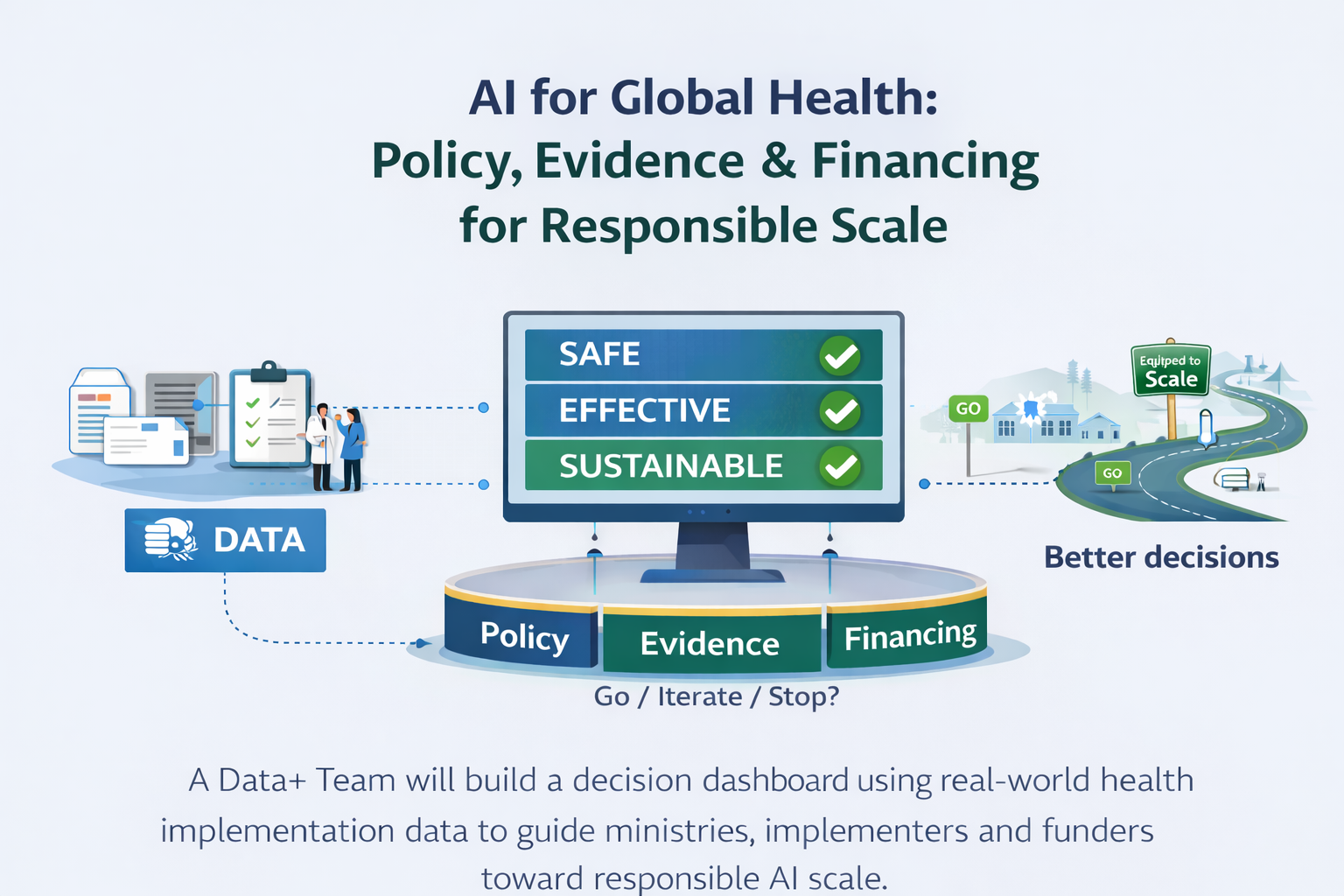

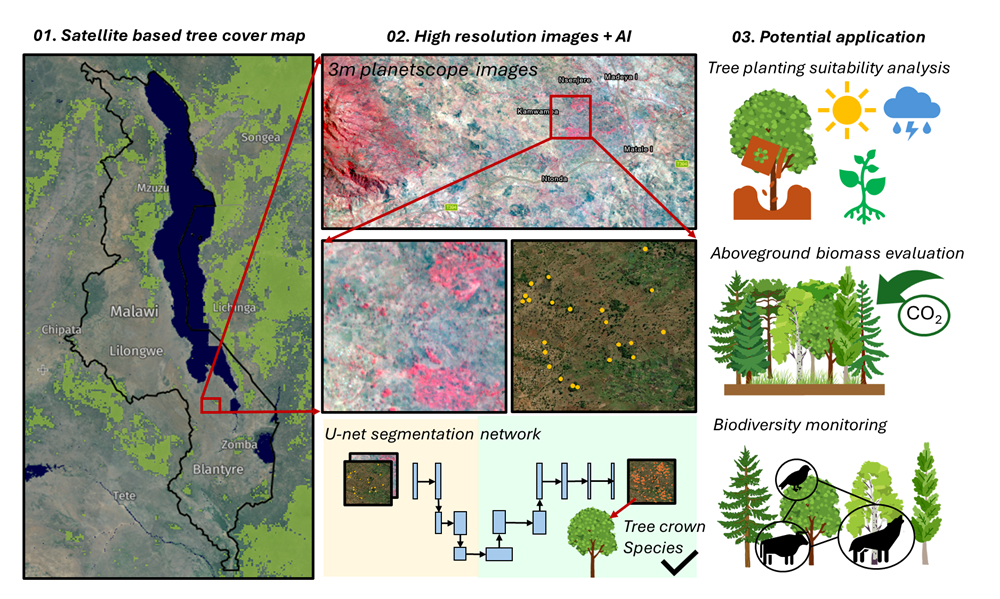

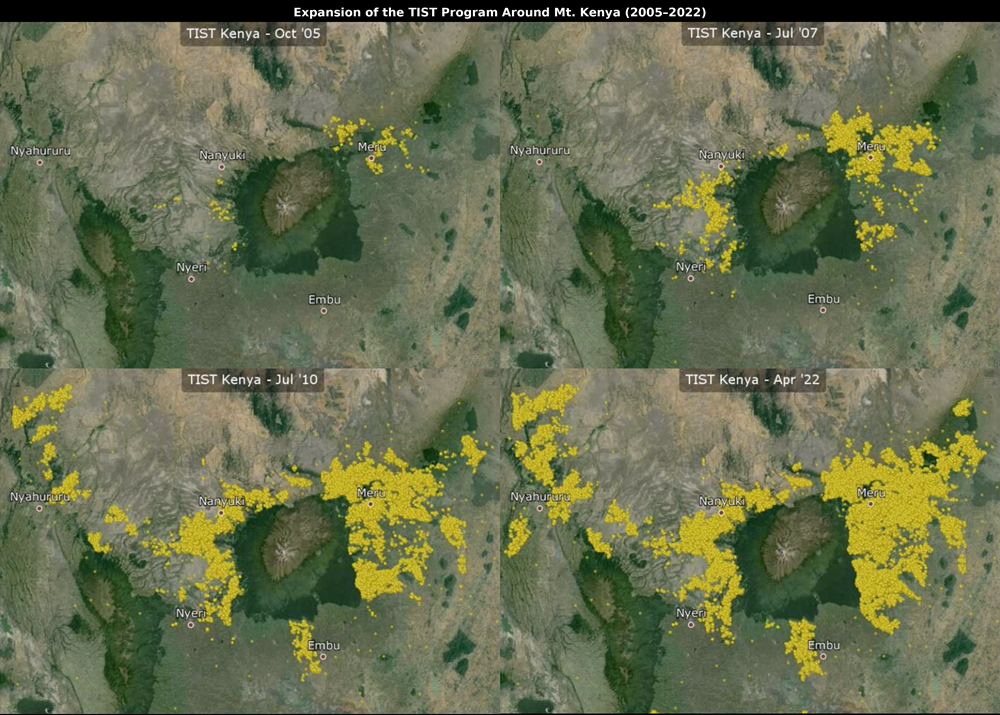



Showing 1-20 of 311 results