Angelo Bonomi (Chemistry), Remy Kassem (ECE, Math), and Han (Alessandra) Zhang (Biology, CompSci) spent ten weeks analyzing data from social networks for communities of people facing chronic conditions. The social network data, provided by MyHealth Teams, contained information shared by community members about their diagnoses, symptoms, co-morbidities, treatments, and details about each treatment.
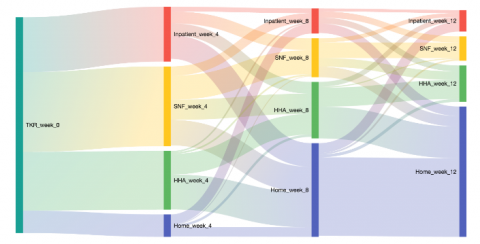
Project Results: The team performed extensive data cleaning, using R and Java, to create a data set suitable for analysis. They then created interactive visualizations of treatment pathways, and built a predictive model for response to medication.
Click here for the Executive Summary
Faculty Lead: Jessie Tenenbaum
Project Manager: Greg Malen
“It was really my first experience working with data, and I found the challenges my students ran into in trying to clean our data surprising. Implementing the code for our primary visualization turned out to be the easiest part of the whole process.” — Greg Malen, Project Manager and Visiting Assistant Professor of Mathematics, Duke Mathematics





