
Mariano Tepper
Related Projects
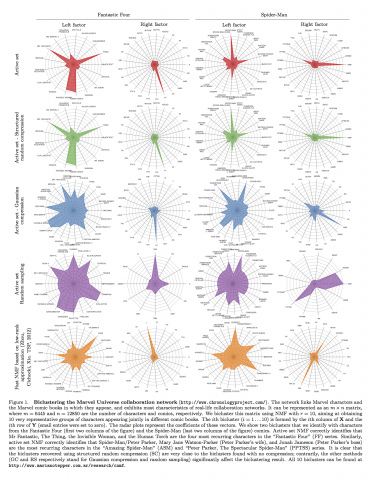
Nonnegative matrix factorization (NMF) has an established reputation as a useful data analysis technique in numerous applications. However, its usage in practical situations is undergoing challenges in recent years.The fundamental factor to this is the increasingly growing size of the datasets available and needed in the information sciences. To address...